Du homelab à l’infrastructure structurée
Par Marco F
Au départ, il s’agissait simplement de disposer de quelques machines virtuelles pour tester des outils et travailler certains sujets. Puis les choses se sont élargies : supervision, ITSM / inventaire scénarios réseau isolés, tests de sécurité.
Petit à petit, le réseau “à plat” a montré ses limites. La mise en place de VLAN et de règles firewall explicites est arrivée naturellement pour garder une architecture lisible.
Une fois le réseau structuré, un autre point est apparu. Recréer une machine revenait toujours aux mêmes étapes : choisir le bon VLAN, attribuer une IP cohérente, installer les agents, rattacher à la supervision, appliquer la configuration de base…
Certaines machines étaient déjà déployées avec Vagrant ou configurées via cloud-init. Ça fonctionnait, mais c’était ponctuel et dispersé. L’idée a été de profiter de cette infra pour passer à un workflow plus “durable” : Terraform pour provisionner sur Proxmox, Ansible pour configurer, et un socle qui évolue dans le temps (au lieu de refaire les mêmes setups à la main).
Le point important : je n’ai pas construit ça autour d’un budget “lab premium”. Aujourd’hui, l’investissement matériel se résume essentiellement à un switch manageable et quelques câbles réseau. Le reste, c’est du matériel que j’avais déjà — notamment un vieux PC portable reconditionné pour l’occasion.
L’idée n’était pas d’avoir une infrastructure parfaite dès le départ, mais un environnement cohérent, propre et exploitable, même avec des ressources limitées.
Une base modeste, pas un choix définitif
Ce PC portable n’a évidemment pas vocation à rester le cœur de l’infrastructure indéfiniment. À moyen terme, l’objectif est de le remplacer par un — idéalement deux — mini PC plus adaptés au rôle de serveur, afin de monter un cluster Proxmox et mutualiser les ressources (notamment la RAM, qui est aujourd’hui le principal facteur limitant).
Mais pour se former, expérimenter, structurer une vraie architecture réseau et mettre en place des services concrets, ce setup est largement suffisant.
Mon objectif est de partager l’avancée de ce projet et de montrer qu’en faisant quelques compromis, il est possible de monter un lab sérieux en limitant les dépenses.
Sommaire
Un tour d’horizon complet (et lisible), avec assez de technique pour comprendre… sans transformer ça en manuel.
- 1) Le point de départ
- 2) Mon matériel et mes contraintes réelles
- 3) Vue d’ensemble (topologie)
- 4) Réseau : VLAN, router-on-a-stick et logique de flux
- 5) Accès et point d’administration
- 6) Services déployés
- 7) Infrastructure as Code : Terraform + Ansible + Vault
- 8) Supervision : auto-enrôlement des agents via API
- 9) Ce que le lab me permet de travailler
- 10) Ce que j’améliore ensuite
1. Le point de départ
L’objectif de départ était simple : pouvoir monter (ou reconstruire) une VM/LXC propre et isolée, sans repartir de zéro à chaque fois — et sans que ça devienne un “projet” à part entière.
Les raisons (très concrètes) :
- veille technologique (tester une stack, une version, un outil)
- formation continue
- reproduction de scénarios réseau
- labs “sécurité” isolés
- tests d’outils de supervision et d’automatisation
Au début, c’était une VM par-ci, une autre par-là. Puis c’est devenu régulier… et ça a commencé à peser sur l’organisation du reste (réseau, accès, supervision, cohérence).
Retaper un vieux laptop pour en faire un hyperviseur
Plutôt que d’acheter immédiatement du matériel dédié, le plus rentable était de commencer avec ce qui traînait déjà — quitte à accepter des compromis. L’avantage : ça permet de démarrer vite, à moindre coût, et surtout de clarifier les besoins réels avant d’investir.
- un Acer Aspire A315 (écran cassé)
- 12 Go de RAM après upgrade
- un SSD récupéré
- aucun budget supplémentaire
Proxmox VE s’est imposé pour une raison très simple : centraliser les labs au lieu d’éparpiller des VMs sur plusieurs machines.
J’ai détaillé tout ça dans un article dédié :
Installer Proxmox sur un vieux portable
Très vite, les habitudes “lab” se mettent en place :
- création de templates Proxmox
- usage de cloud-init
- images Debian propres
- multiplication des VMs selon les besoins
Ça fonctionne — mais ce n’est pas encore structuré : chaque nouveau service demande du temps, et la cohérence n’est jamais garantie du premier coup.
Quand le “lab” commence à ressembler à une infra
Créer une VM n’est pas le plus dur. Le plus dur, c’est de la rendre fiable et homogène dans le temps.
Même en partant de templates, remettre une machine “au bon niveau” revient souvent aux mêmes étapes :
- réseau (VLAN, DNS, routage, accès)
- installation / configuration des services
- agents (supervision / inventaire)
- rattachement à Zabbix / GLPI
- durcissement minimal (ce qui est exposé, ce qui ne l’est pas)
Petit à petit, le lab n’est plus seulement un terrain de test : il devient segmenté, supervisé, routé via firewall… et surtout, réellement utilisé.
La contrainte réelle : la RAM
Le CPU tient. Le stockage tient. La mémoire, elle, devient vite le goulot d’étranglement.
Entre Zabbix, GLPI, les environnements de test, les machines Windows, la segmentation réseau, et des VMs type Kali, la RAM devient rapidement le facteur limitant.
Deux axes s’imposent naturellement :
- optimiser (LXC plutôt que VM quand c’est pertinent)
- préparer une architecture évolutive sans tout reconstruire
Anticiper l’évolution matérielle
Le laptop fait le job… mais l’idée, à terme, est d’éviter que toute l’infra dépende d’une seule machine.
À moyen terme, l’objectif est clair : remplacer le laptop par un — idéalement deux — mini-PC plus adaptés, monter un cluster Proxmox, mutualiser les ressources (RAM en priorité), et préparer la suite (stacks containerisées / orchestration).
Tant que le socle est encore en construction, le plus important est surtout de garder une trajectoire lisible : partir simple, stabiliser, puis ajouter de la capacité au moment où les limites deviennent factuelles.
Ce que je ne voulais pas
- Une infra “parfaite sur le papier” mais pénible à vivre
- Un lab surdimensionné pour le principe
- Empiler des couches d’abstraction inutiles
- Acheter du matériel juste pour l’image
Ce que je voulais
- Une base cohérente et compréhensible
- Un setup reproductible (ou réparable) rapidement
- Une infra évolutive sans tout reconstruire
- Compatible avec du matériel de récup
2. Mon matériel et mes contraintes réelles
Permanent
Ce qui doit rester dispo en continu.
- Zabbix (supervision)
- GLPI (ITSM / inventaire)
- OPNsense (routage inter-VLAN + firewall)
- Point d’administration (RPi4)
- DNS interne (Unbound)
- Reverse proxy (HAProxy)
Principalement en LXC pour économiser la RAM (sauf OPNsense).
Ponctuel
Lourd, utile, mais pas H24.
- VM Windows / RDP
- Tests applicatifs
- Stacks containerisées (ex : Prometheus/Grafana)
Déployé “au besoin”, parfois sur VMware Fusion (sur une autre machine) pour soulager Proxmox.
Sécurité / pentest
Isolé, contrôlé, réversible.
- Metasploitable & cibles vulnérables
- Scénarios réseau isolés
- Kali : selon le besoin (souvent hors Proxmox)
Le vrai levier, c’est VLAN + règles OPNsense (fermer/ouvrir proprement).
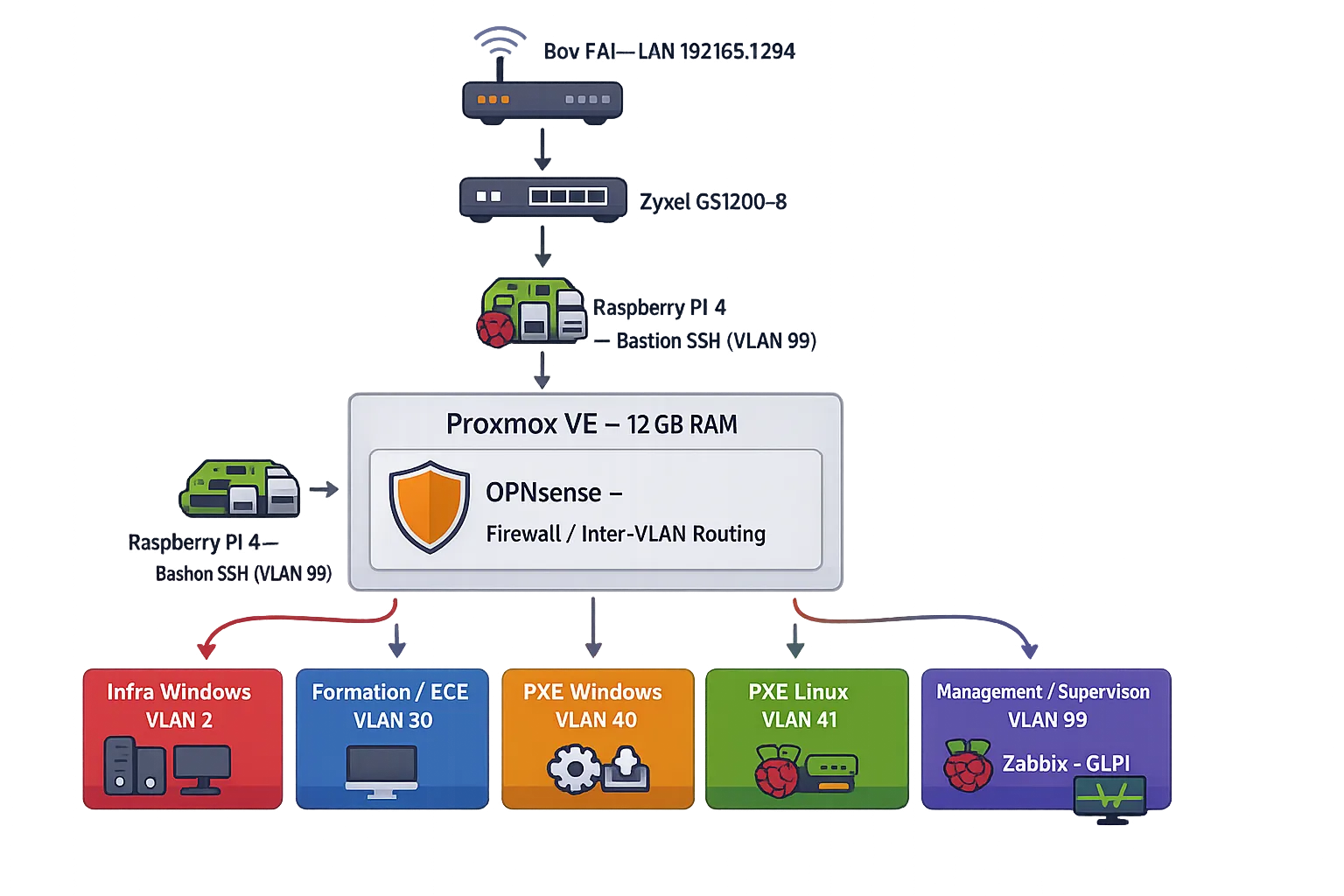
3. Vue d’ensemble (topologie)
L’infrastructure tient sur une architecture simple mais structurée : un hyperviseur principal, un firewall virtuel, des VLAN segmentés, et un point d’administration dédié.
OPNsense est positionné derrière la box Internet (double NAT assumé). Son interface WAN est sur le réseau 192.168.1.0/24, LAN principal (vers la box) et les VLAN (99 + labs) sont côté LAN d’OPNsense.
Et côté “confort d’usage”, deux briques font vite la différence : un DNS interne (pour arrêter de vivre en IP) et un reverse proxy (pour exposer des services proprement derrière un point d’entrée unique).
LAN principal
192.168.1.232— Proxmox (pve-01)192.168.1.100— OPNsense
VLAN Services
10.99.99.1— Gateway10.99.99.4— RPi4 (point d’admin)10.99.99.112— GLPI10.99.99.114— Zabbix
Chaque usage a son segment, c’est ce qui me permet de fermer totalement un environnement si nécessaire.
4. Réseau : VLAN, router-on-a-stick et logique de flux
À partir du moment où le nombre de services grandit, laisser tout à plat devient vite pénible. Segmenter permet surtout de garder la main : isoler, ouvrir, refermer, sans effet de bord.
Le vrai intérêt, ici, c’est la segmentation contrôlable : je peux lancer une stack, l’isoler dans un VLAN, ouvrir uniquement ce qui est nécessaire, puis refermer proprement quand j’ai fini.
Principe
Chaque usage a son segment réseau. Les flux entre segments sont explicites, pas “par défaut”.
Objectif
Garder une base stable (services permanents) et pouvoir ouvrir/fermer les labs ponctuels sans friction.
Levier
VLAN + règles OPNsense : c’est ça qui rend le lab “pilotable”, pas une liste interminable de configs.
Vue logique des segments
Je ne détaille pas un plan d’adressage complet, mais voici les segments les plus structurants, ceux qui expliquent comment je sépare les usages.
LAN principal
192.168.1.0/24
- Box / accès Internet
- Proxmox (hôte)
- OPNsense (interface non taggée sur ce réseau)
VLAN 99 — Services / admin
10.99.99.0/24
- Gateway : OPNsense (10.99.99.1)
- RPi4 (point d’admin) (10.99.99.4)
- GLPI (10.99.99.112)
- Zabbix (10.99.99.114)
VLAN “labs” — Ponctuel
10.x.x.0/24
- machines vulnérables (ex : Metasploitable)
- scénarios réseau isolés
- environnements Windows / RDP au besoin
Router-on-a-stick (sans mystère)
OPNsense est une VM sur Proxmox. Le switch transporte les VLAN via un trunk. OPNsense reçoit les tags, route entre VLAN, applique les règles firewall, et fait le NAT vers l’extérieur.
Concrètement, les VLAN sont transportés via un trunk entre le switch et Proxmox :
- Port du switch configuré en trunk (VLAN taggés)
- Bridge Proxmox (ex : vmbr0) configuré en VLAN-aware
- Interface de la VM OPNsense connectée à ce bridge
- Sous-interfaces VLAN créées côté OPNsense
Les tags arrivent donc directement dans la VM firewall, qui assure le routage inter-VLAN et le filtrage.
Ce n’est pas “l’architecture parfaite production”, mais c’est une approche réaliste et très lisible pour apprendre et faire évoluer le lab : un seul point qui route, filtre, et journalise.
Logique de sécurité
Je ne liste pas toutes les règles, mais la logique tient en deux blocs : ce qui est fermé par défaut, et ce qui est ouvert explicitement.
Par défaut
- pas d’accès inter-VLAN “libre”
- pas d’exposition directe des services internes
- un lab peut être coupé sans impacter les services permanents
Ouvert explicitement
- point d’admin → services (SSH / web / API selon besoin)
- services → Internet (updates / dépôts)
- WireGuard → VLAN management (accès à distance)
L’idée, c’est de pouvoir répondre à une question simple : qui peut parler à qui, et pourquoi.
5. Accès et point d’administration
Dans un contexte “entreprise”, on parlerait de bastion. Ici je préfère parler de point d’administration : un endroit stable d’où je pilote l’infra, sans dépendre d’une VM et sans ouvrir mon poste principal partout.
Point important : je fais ça comme ça parce que j’ai un Raspberry Pi 4 toujours allumé. Si je ne l’avais pas, j’aurais simplement autorisé mon poste d’admin à accéder aux VLAN nécessaires, avec des règles OPNsense strictes. Les deux approches sont valables.
Pourquoi le Raspberry Pi 4 est pratique (dans mon cas)
Le Pi 4 est branché en filaire, stable, et indépendant des services hébergés. Je l’utilise comme “point d’entrée” cohérent pour tout ce qui est admin et outillage.
Ce que ça simplifie
- un point stable pour SSH / clés / scripts
- Terraform + Ansible centralisés (par simplicité)
- doc et notes au même endroit
- accès cohérent aux VLAN via le tunnel WireGuard
Ce que ce n’est pas
- un modèle “enterprise” copié-collé
- une DMZ complète et définitive
- du zero trust end-to-end
L’objectif reste : contrôle + lisibilité, pas la surenchère.
Où il se place dans le réseau
Mon Mac reste sur le LAN principal (réseau box). C’est mon poste “utilisateur”, et je n’ouvre que les flux nécessaires vers le VLAN 99, principalement pour accéder au point d’administration (RPi4).
Le point d’admin est dans le VLAN d’administration (VLAN 99). Ça me permet d’administrer les services “permanents” sans ouvrir des accès transverses inutiles.
Je garde une logique simple : deny par défaut, et j’ouvre uniquement les flux nécessaires, généralement dans un seul sens (admin → service).
Flux typiques
- SSH vers les LXC/VM de service
- HTTP/HTTPS vers GLPI et Zabbix
- API Zabbix (pour l’automatisation)
Accès à distance
Quand je ne suis pas sur le LAN, je passe par WireGuard.
Ça me permet d’exploiter le lab “comme si j’étais à la maison”, sans exposer les services internes.
6. Services déployés
Je garde une règle simple : un socle de services permanents, bien compris et bien maintenu. Le reste tourne “au besoin” — pas par manque d’intérêt, mais parce que sur une machine à 12 Go de RAM, tu dois arbitrer en permanence entre confort et stabilité.
L’idée n’est pas de me limiter à “2 services stables”, mais d’éviter le piège classique du homelab : installer plein d’outils, puis ne plus savoir lesquels sont vraiment utilisés, ni dans quel état.
Permanent
Ce qui sert à piloter et garder une base stable.
Ponctuel
Ce qui est utile, mais pas nécessaire 24/7.
Isolé
Labs, pentest, cibles vulnérables : contrôlé, réversible.
Pourquoi GLPI et Zabbix (et pas “un truc plus simple”)
J’ai testé / hésité avec d’autres outils (et je continue), mais GLPI + Zabbix ont un avantage important dans un lab qui grossit : ils donnent une structure et un retour immédiat sur ce qui tourne réellement.
GLPI — mon usage concret
- inventaire “propre” : ce qui existe, où ça tourne, à quoi ça sert
- suivi des changements : “j’ai modifié quoi ? quand ? pourquoi ?”
- mémos techniques : ports, identifiants de service, dépendances
- tickets perso (oui) quand je fais un chantier étalé sur plusieurs jours
Le gain principal : je ne dépends pas de ma mémoire quand je reviens sur un service 3 semaines plus tard.
Zabbix — ce que ça m’apporte au quotidien
- voir rapidement si “c’est le réseau” ou “c’est le service”
- surveiller l’hyperviseur (
pve-01) : charge, RAM, disque - confirmer qu’une règle firewall n’a pas cassé un flux
- avoir des graphes/événements quand je fais des tests (labs / pentest)
Je ne cherche pas la supervision parfaite : je veux un tableau de bord fiable pour diagnostiquer vite.
DNS et reverse proxy : les deux briques qui rendent le lab vraiment pratique au quotidien
La segmentation réseau et le routage inter-VLAN posent une base propre. Mais à l’usage, accéder aux services uniquement via des IP ou en multipliant les tunnels SSH pour chaque interface web devient vite peu pratique.
Mettre en place un DNS interne et un reverse proxy permet d’éviter cette accumulation de tunnels et de centraliser l’accès aux services derrière des URL claires et cohérentes.
Pour rendre l’ensemble plus structuré, j’ai ajouté deux composants complémentaires :
Unbound pour le DNS local et HAProxy pour le reverse proxy.
L’objectif est simple : disposer d’URL lisibles (glpi.mof.lab, zabbix.mof.lab, etc.)
et d’un point d’entrée unique côté LAN, au lieu d’exposer des ports au cas par cas.
Deux Unbound, deux rôles
Unbound sur OPNsense : DNS central du lab, intégré au routage inter-VLAN. Il assure la résolution locale ainsi que le relais vers l’extérieur.
Unbound sur le Raspberry Pi 4 : DNS secondaire / point d’appui côté administration, pas obligatoire mais utile pour conserver une résolution fonctionnelle si une partie du lab devient indisponible.
Concrètement, cela repose surtout sur quelques overrides pour les services internes, sans complexifier inutilement la configuration.
HAProxy : terminaison TLS et routage par nom
- Terminaison TLS (certificats centralisés).
- Routage par nom de domaine (SNI / hostnames).
- Redirection vers les services internes (ex. VLAN 99) sans ouvrir de ports supplémentaires.
Au passage, ça m’a obligé à clarifier deux ou trois points (certificats, DNS, règles de routage), parce qu’un reverse proxy ne pardonne pas trop quand quelque chose est incohérent. Je reste sur une approche simple, juste assez propre pour que l’accès aux services soit fluide au quotidien.
7. Infrastructure as Code : Terraform + Ansible + Vault
Les templates Proxmox sont très pratiques. Couplés à cloud-init, on peut monter une VM assez vite. Mais ça reste difficile à versionner proprement, et surtout, je m’étais habitué à une organisation type Vagrant/VirtualBox.
L’idée avec Terraform et Ansible n’était pas de compliquer, mais de retrouver un workflow où créer ou reconstruire un service ne ressemble plus à une soirée entière de réglages à la main.
Je veux pouvoir déployer vite, rester cohérent, et savoir exactement comment une machine a été construite.
Terraform
Provisionner : créer les LXC, poser le réseau, l’IP, le VLAN tag, les ressources.
Ansible
Configurer : base OS, packages, services, agents, templates, idempotence.
Vault
Séparer les secrets du reste (DB, API), sans polluer le repo.
resource "proxmox_virtual_environment_container" "glpi" { node_name = "pve-01" vm_id = 112 initialization { hostname = "glpi-its-01" ip_config { ipv4 { address = "10.99.99.112/24" gateway = "10.99.99.1" } } } network_interface { bridge = "vmbr0" vlan_id = 99 } unprivileged = true features { nesting = true } }
Extrait de ressource Terraform simple
8. Supervision : auto-enrôlement des agents via API (Zabbix)
Installer un agent Zabbix est déjà très utile : on récupère des métriques, on supervise l’hôte, on a une visibilité immédiate.
L’auto-enrôlement n’est pas une obligation. Dans mon cas, c’est surtout une manière d’explorer les possibilités de l’API Zabbix et d’aligner la supervision avec le reste de ma logique Infrastructure as Code.
Provisioning (Proxmox)
Terraform crée les LXC/VM sur Proxmox (réseau, VLAN tag, IP, ressources). Ansible enchaîne sur la configuration OS et services.
Supervision (Zabbix)
Une fois l’hôte prêt, l’agent Zabbix s’enregistre automatiquement via des règles pilotées par l’API Zabbix (orchestrée par Ansible).
Concrètement : je déploie un host → l’agent annonce une HostMetadata
(ex : proxmox, services) →
Zabbix l’ajoute automatiquement au bon groupe
et lui applique les templates adaptés.
Mapping côté Ansible (extrait)
- name: Bootstrap GLPI hosts: glpi become: true roles: - common - glpi - zabbix_agent
Pourquoi aller jusque-là ?
Au début, j’ajoutais chaque machine à la main dans l’interface : host, groupe, template, inventaire… ça fonctionne très bien.
Mais puisque je déploie déjà mes machines avec Terraform et Ansible, j’ai trouvé cohérent d’automatiser aussi leur intégration côté supervision. Ce n’est pas une nécessité absolue — c’est une façon d’explorer l’outil, et de garder une logique homogène du début à la fin.
9. Ce que le lab me permet de travailler
J’ai volontairement gardé l’infra “simple” : un hyperviseur, un firewall, des VLAN, quelques services pivots. Mais ce socle est suffisant pour travailler des sujets très concrets — et surtout, pour les relier entre eux.
L’objectif n’est pas d’ouvrir une grande partie “cyber” dans cet article, mais d’expliquer ce que cette infra me permet réellement de pratiquer au quotidien.
Réseau & architecture
- segmentation (VLAN), trunk, VLAN-aware bridge
- routage inter-VLAN & NAT (router-on-a-stick)
- règles firewall lisibles (deny par défaut, ouvertures explicites)
- observabilité des flux (logs) pour valider “qui parle à qui”
Systèmes & exploitation
- templates & cloud-init (rebuild rapide)
- LXC vs VM selon le besoin (arbitrages RAM)
- séparation “permanent” / “ponctuel” pour garder le lab stable
- accès admin cohérent (RPi4 + WireGuard)
- DNS interne + reverse proxy (ça paraît “annexe”, mais ça structure vite)
Automatisation & IaC
- déployer/retirer des stacks containerisées “outil” (observabilité, tests) de façon réversible
- Terraform : provisionner (réseau, IP, VLAN, ressources)
- Ansible : configurer (idempotence, rôles, standardisation)
- secrets séparés via Vault (sans polluer le repo)
- un workflow “rebuild” plutôt que du tuning à la main
Sécurité (au bon niveau)
- environnements isolés (VLAN “labs”) pour tester sans risque
- ouvrir / refermer proprement une fenêtre de test (règles + logs)
- durcissement minimal sur ce qui reste permanent (surface d’expo réduite)
Les scénarios “pentest” (cibles vulnérables, captures, etc.) seront traités dans un article dédié, avec les preuves visuelles au bon endroit.
En clair : ce lab me sert autant à apprendre qu’à valider. Je peux faire une hypothèse (“cette règle isole vraiment ?”, “cet agent s’enrôle bien ?”) et le vérifier sur une infra segmentée, instrumentée, et reproductible.
Observabilité & stacks containerisées
Le lab me permet aussi de travailler une logique “stack outil” : déployer une solution d’observabilité (ex : Prometheus / Grafana), instrumenter un test précis, puis démonter proprement l’environnement.
Ce n’est pas un service critique permanent — c’est un terrain d’expérimentation contrôlé. L’intérêt est surtout méthodologique : déployer → observer → analyser → retirer.
Pourquoi c’est intéressant pédagogiquement :
- instrumenter une charge ou un test réseau
- valider l’impact d’une règle firewall ou d’un changement d’archi
- travailler la logique “stack réversible” (infra jetable, propre, maîtrisée)
Kubernetes s’inscrit dans cette continuité : non pas comme objectif “buzzword”, mais comme étape logique pour industrialiser le déploiement de stacks containerisées, dès que le socle matériel évoluera.
10. Ce que j’améliore ensuite
L’infra actuelle fonctionne, mais elle reste contrainte par le matériel. L’idée n’est pas de tout refaire : je veux garder le même socle (segmentation + routage + services pivots), et augmenter progressivement la capacité là où ça bloque vraiment.
Priorité : la RAM
Aujourd’hui, c’est le goulot. Donc je privilégie : LXC quand possible, et “ponctuel” quand c’est lourd.
Priorité : éviter le point unique
Une seule machine, ça marche… jusqu’au jour où tu veux migrer, maintenir, ou juste tester sans stress.
Évolution matérielle : mini-PC (1 puis idéalement 2)
Le laptop est un bon point de départ, mais à terme je veux basculer sur du matériel plus adapté : mini-PC, conso raisonnable, plus de RAM, et un setup plus propre côté stockage.
Dans quel ordre (réaliste)
- ajouter un premier mini-PC pour soulager et migrer progressivement
- ajouter un second pour tester cluster/migrations sans stress
- standardiser stockage + sauvegardes (et arrêter les “bricolages”)
Articles “zoom” à venir
Ce billet pose la vue d’ensemble. Je détaillerai certains sujets dans des articles dédiés, avec des schémas et captures plus précis :
- router-on-a-stick + règles OPNsense “type” (avec captures et avant/après)
- workflow Terraform/Ansible (structure repo, variables, exemples complets)
- auto-enrôlement Zabbix (API, groupes, templates, HostMetadata)
- DNS + reverse proxy (Unbound + HAProxy) : le minimum viable pour avoir des services “propres”
- labs isolés “sécurité” : périmètre, fenêtres de test, observabilité (sans surenchère)
Conclusion
Ce homelab est devenu une petite infrastructure structurée, non pas par “complexité”, mais par besoin : segmenter, piloter, reconstruire, et observer ce qui se passe.
Même avec un matériel modeste, le combo Proxmox + OPNsense + VLAN + IaC me permet de travailler des sujets transverses (réseau, systèmes, automatisation, supervision) dans un environnement cohérent — et surtout, reproductible.